

التعليقات المغلقة هي تقنية فعّالة لتحسين إمكانية الوصول، والتفاعل، والاحتفاظ بالمعلومات أثناء العروض التقديمية والفعاليات الحية. هذا، إلى جانب تغير عادات استهلاك الفيديو في مجال البث الفيديوي، قد سرّع مؤخرًا اعتماد الترجمة التلقائية المدعومة بالذكاء الاصطناعي في الفعاليات الحية والاجتماعات التجارية.
ولكن عندما يتعلق الأمر باختيار مزوّد لاجتماعك أو فعاليتك الخاصة، فإن السؤال الأكثر شيوعًا هو: ما مدى دقة التعليقات الحية التلقائية؟
الإجابة السريعة هي أن، تحت الظروف المثالية، يمكن للتعليقات التلقائية في اللغات المنطوقة أن تحقق دقة تصل إلى 98٪ كما يتم تقييمها بواسطة معدل خطأ الكلمات (WER).
نعم، هناك إجابة طويلة، أكثر تعقيدًا قليلاً. في هذه المقالة، نريد أن نقدم لك نظرة عامة على كيفية قياس الدقة، والعوامل التي تؤثر على الدقة، وكيفية رفع مستوى الدقة إلى آفاق جديدة.
في هذه المقالة
- كيف يعمل الترميز التلقائي
- ما هو ما يُعتبر جودة ترميز جيدة؟
- ما العوامل التي تؤثر على الدقة؟
- قياس دقة الترجمات التلقائية
- فهم معدل خطأ الكلمات (WER)
- الحصول على ترجمات مغلقة دقيقة للغاية لفعالياتك الحية
قبل أن نتعمق في الأرقام، دعنا نعود خطوة إلى الوراء وننظر إلى كيفية عمل التعليقات التلقائية.
كيف يعمل الترميز التلقائي
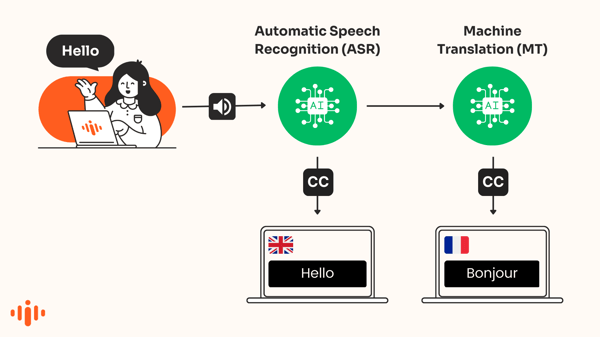
ترجمات تلقائية
تحول التعليقات التلقائية الكلام إلى نص يُظهر على الشاشة في الوقت الحقيقي بنفس لغة الكلام. ASR - التعرف الآلي على الكلام - هو نوع من الذكاء الاصطناعي يُستخدم لإنتاج هذه النصوص للجمل المنطوقة.
التكنولوجيا، المعروفة غالبًا باسم "تحويل الكلام إلى نص"، تُستخدم للتعرف تلقائيًا على الكلمات في الصوت وتحويل الصوت إلى نص.
ترجمات مترجمة بالذكاء الاصطناعي
محركات الترجمة المدعومة بالذكاء الاصطناعي تقوم تلقائيًا بترجمة الترجمات التي تظهر بلغة مختلفة. يُعرف ذلك أيضًا بالترجمات الفرعية المترجمة آليًا أو الترجمات المترجمة آليًا.
مقال موصى به
لماذا يجب عليك التفكير في إضافة ترجمات حية إلى حدثك القادم
في هذه المقالة، نحن نتناول الترجمات التلقائية. إذا كنت ترغب في معرفة دقة الترجمات التي تم ترجمتها بالذكاء الاصطناعي، تحقق من هذه المقالة.
ما هو ما يُعتبر جودة ترميز جيدة؟
قامت لجنة الاتصالات الفدرالية (FCC) بتحديد الخصائص الأساسية في عام 2014 لتحديد ما إذا كانت الترجمة النصية "ممتازة":
- الدقة -يجب أن تتطابق الترجمات مع الكلمات المنطوقة، إلى أقصى حد ممكن
- اكتمال - تُظهر الترجمات من بداية البث حتى نهايته، بأقصى قدر ممكن من الشمولية.
- موضع - الترجمات لا تحجب المحتوى البصري المهم وتكون سهلة القراءة.
- المزامنة - تتطابق الترجمات مع مسار الصوت وتظهر بسرعة قابلة للقراءة.
صورة: ترجمات حية مترجمة بالذكاء الاصطناعي أثناء ندوة عبر الإنترنت
ما العوامل التي تؤثر على الدقة؟
محرك الذكاء الاصطناعي المختار
ليس كل محركات تحويل الكلام إلى نص تنتج نتائج متطابقة. بعضها أفضل بشكل عام، بينما البعض الآخر أفضل في لغات معينة. وحتى عند استخدام نفس المحرك، يمكن أن تختلف النتائج بشكل كبير اعتمادًا على اللهجات، مستويات الضوضاء، المواضيع، وما إلى ذلك.
لهذا السبب، في Interprefy، نقوم دائمًا بمقارنة أفضل المحركات لتحديد أيها يولد أدق النتائج. ونتيجة لذلك، يمكن لـ Interprefy تقديم أفضل حل للمستخدمين للغة المحددة، مع مراعاة عوامل مثل الكمون والتكلفة. في الإعدادات المثالية، لاحظنا دقة ثابتة تصل إلى 98٪ لعدة لغات.
جودة إدخال الصوت
مطلوب إدخال عالي الجودة لتقنية التعرف الآلي على الكلام لإنتاج مخرجات ذات جودة. إنه' بسيط: كلما ارتفعت الجودة والوضوح للصوت والصوت، كلما تحسنت النتائج.
- جودة الصوت - مشابهًا لـ الترجمة الفورية للمؤتمرات، أجهزة إدخال الصوت السيئة، مثل الميكروفونات المدمجة في الحواسيب يمكن أن يكون لها تأثير سلبي.
- نطق واضح & نطق واضح - المقدمون الذين يتحدثون بصوت عالٍ، وبوتيرة مناسبة، وبوضوح، عادةً ما يتم وضع ترجمات نصية بدقة أعلى.
- الضوضاء الخلفية - ضجيج ثقيل، نباح كلاب، أو تقليب أوراق يتم التقاطه بالميكروفون يمكن أن يضعف جودة إدخال الصوت بشكل كبير.
- اللهجات - المتحدثون الذين يمتلكون لهجات غير عادية أو قوية، بالإضافة إلى المتحدثين غير الأصليين، يسببون مشاكل للعديد من أنظمة التعرف على الصوت.
- التحدث المتداخل - إذا تحدث شخصان فوق بعضهما البعض، سيواجه النظام صعوبة كبيرة في التعرف على المتحدث الصحيح بدقة.
مقال موصى به
ما مدى دقة الترجمات النصية في Zoom و Teams و Interprefy؟
كيفية قياس دقة الترجمات التلقائية
المقياس الأكثر شيوعًا لقياس دقة نظام التعرف على الكلام (ASR) هو معدل الخطأ في الكلمات (WER)، والذي يقارن النص الفعلي للمتحدث بنتيجة مخرجات نظام التعرف على الكلام.
على سبيل المثال، إذا كان 4 من كل 100 كلمة خاطئة، فإن الدقة ستكون 96٪.
فهم معدل خطأ الكلمات (WER)
يحدد WER أقصر مسافة بين نص النص المفرغ الذي تم إنشاؤه بواسطة نظام التعرف على الصوت ونص مرجعي تم إنتاجه بواسطة إنسان (الواقع الأرضي).
يقوم مقياس معدل الخطأ في الكلمات (WER) بمواءمة تسلسلات الكلمات المحددة بشكل صحيح على مستوى الكلمة قبل حساب إجمالي عدد التصحيحات (الاستبدالات والحذف والإدخالات) المطلوبة لمواءمة النص المرجعي والنص المنسوخ بالكامل. ثم يُحسب الـ WER كنسبة عدد التعديلات اللازمة إلى إجمالي عدد الكلمات في النص المرجعي. عادةً ما يشير انخفاض الـ WER إلى نظام التعرف على الصوت أكثر دقة.
مثال على معدل الخطأ اللفظي: 91.7٪ دقة
دعونا نأخذ مثالًا على معدل خطأ الكلمات بنسبة 8.3٪ - أو دقة 91.7٪ ونقارن الاختلافات بين النص الأصلي للخطاب والترجمات التي أنشأها نظام التعرف التلقائي على الكلام (ASR):
| النص الأصلي: | مخرجات تسميات ASR: |
| على سبيل المثال، أنا أفعل أحب فقط الاستخدام المحدود للغاية للـ الأساسيات المقدمة، أرغب في الخوض في نقطة معينة بمزيد من التفصيل، وأخشى أن أنا أدعو على البرلمانات الوطنية الفردية لتصديق الاتفاقية فقط بعد توضيح دور المحكمة الأوروبية قد يسبب آثارًا ضارة جدًا. | على سبيل المثال، أنا أنا أيضًا أرغب فقط في استخدام محدود جدًا من الإعفاءات المقدمة أود الخوض في نقطة معينة بمزيد من التفصيل أخشى أن ال نداء على برلمانات الدول الفردية لتصديق الاتفاقية فقط بعد توضيح دور المحكمة الأوروبية قد يكون له آثار ضارة جدًا. |
في هذا المثال، فقدت التسميات كلمة واحدة واستبدلت بأربع كلمات:
- القياسات: {'matches': 55, 'deletions': 1, 'insertions': 0, 'substitutions': 4}
- البدائل: [('too', 'do'), ('use', 'used'), ('exemptions', 'essentials'), ('the', 'i')]
- الحذف: ['would']
وبالتالي، يكون حساب معدل الخطأ في الكلمات هو:
WER = (الحذف + الاستبدالات + الإدخالات) / (الحذف + الاستبدالات + المطابقات) = (1 + 4 + 0) / (1 + 4 + 55) = 0.083
يتغاضى مقياس WER عن طبيعة الأخطاء
الآن في المثال أعلاه، ليست كل الأخطاء ذات تأثير متساوٍ.
قد يكون قياس معدل الخطأ في الكلمات (WER) مضللًا لأنه لا يوضح لنا مدى صلة/أهمية الخطأ المعين. الأخطاء البسيطة، مثل التهجئة البديلة لنفس الكلمة (movable/moveable)، لا يُنظر إليها غالبًا كأخطاء من قبل القارئ، بينما قد يكون الاستبدال (exemptions/essentials) أكثر تأثيرًا.
أرقام WER، خاصةً في أنظمة التعرف على الكلام ذات الدقة العالية، يمكن أن تكون مضللة ولا تتطابق دائمًا مع تصورات البشر للصحّة. بالنسبة للبشر، غالبًا ما يكون من الصعب التمييز بين اختلافات مستويات الدقة بين 90٪ و99٪.
معدل الخطأ المتصوَّر للكلمات
قامت Interprefy بتطوير مقياس خطأ مخصص لنظام التعرف على الكلام (ASR) ومحدد للغة يُدعى WER المتصوّر. يحسب هذا المقياس فقط الأخطاء التي تؤثر على فهم الإنسان للكلام وليس جميع الأخطاء. عادةً ما تكون الأخطاء المتصوّرة أقل من WER، وأحيانًا تصل إلى انخفاض بنسبة 50٪. عادةً ما يكون WER المتصوّر بنسبة 5-8٪ غير ملحوظ تقريبًا للمستخدم.
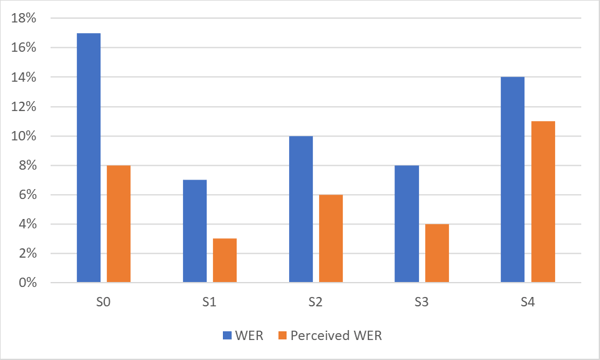
يوضح المخطط أدناه الفرق بين معدل الخطأ اللفظي (WER) ومعدل الخطأ اللفظي المتصور (Perceived WER) لنظام التعرف على الكلام عالي الدقة. لاحظ الفرق في الأداء لمجموعات البيانات المختلفة (S0‑S4) لنفس اللغة.
كما هو موضح في الرسم البياني، فإن معدل الخطأ المتصور من قبل البشر يكون غالبًا أفضل بكثير من معدل الخطأ الإحصائي.
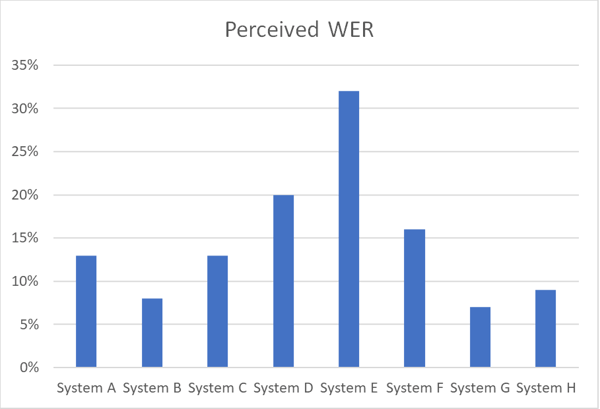
يوضح المخطط أدناه الفروق في الدقة بين أنظمة التعرف على الكلام المختلفة التي تعمل على مجموعة بيانات الكلام نفسها بلغة معينة باستخدام معدل الخطأ اللفظي المتصور.
الحصول على ترجمات مغلقة دقيقة للغاية لفعالياتك الحية
لقد شهدنا دقة بنسبة 97٪ لتسمياتنا التلقائية بفضل الجمع بين حلنا التقني الفريد والعناية التي نقدمها لعملائنا. ألكسندر دافيدوف، رئيس قسم توصيل الذكاء الاصطناعي في Interprefy
إذا كنت تبحث عن الحصول على ترجمات تلقائية دقيقة للغاية أثناء الحدث، فهناك ثلاثة أمور رئيسية يجب أن تأخذها في الاعتبار:
استخدم حلاً رائدًا في فئته
بدلاً من اختيار أي محرك جاهز لتغطية جميع اللغات، اختر مزودًا يستخدم أفضل محرك متاح لكل لغة في حدثك.
هل ترغب في فهم ما يمكن أن يقدمه لك أفضل محرك؟ اقرأ مقالتنا: مستقبل الترجمة الفورية الحية: كيف تُعزز AI من Interprefy إمكانية الوصول
تحسين المحرك
اختر مزودًا يمكنه تعزيز الذكاء الاصطناعي بقاموس مخصص لضمان التقاط أسماء العلامات التجارية والأسماء غير المعتادة والاختصارات بشكل مناسب.
تأكد من جودة إدخال الصوت العالية
إذا كان إدخال الصوت سيئًا، فإن نظام التعرف على الكلام لن يتمكن من تحقيق جودة الإخراج. تأكد من أن الكلام يمكن التقاطه بصوت عالٍ وبوضوح.


 مزيد من روابط التحميل
مزيد من روابط التحميل



